



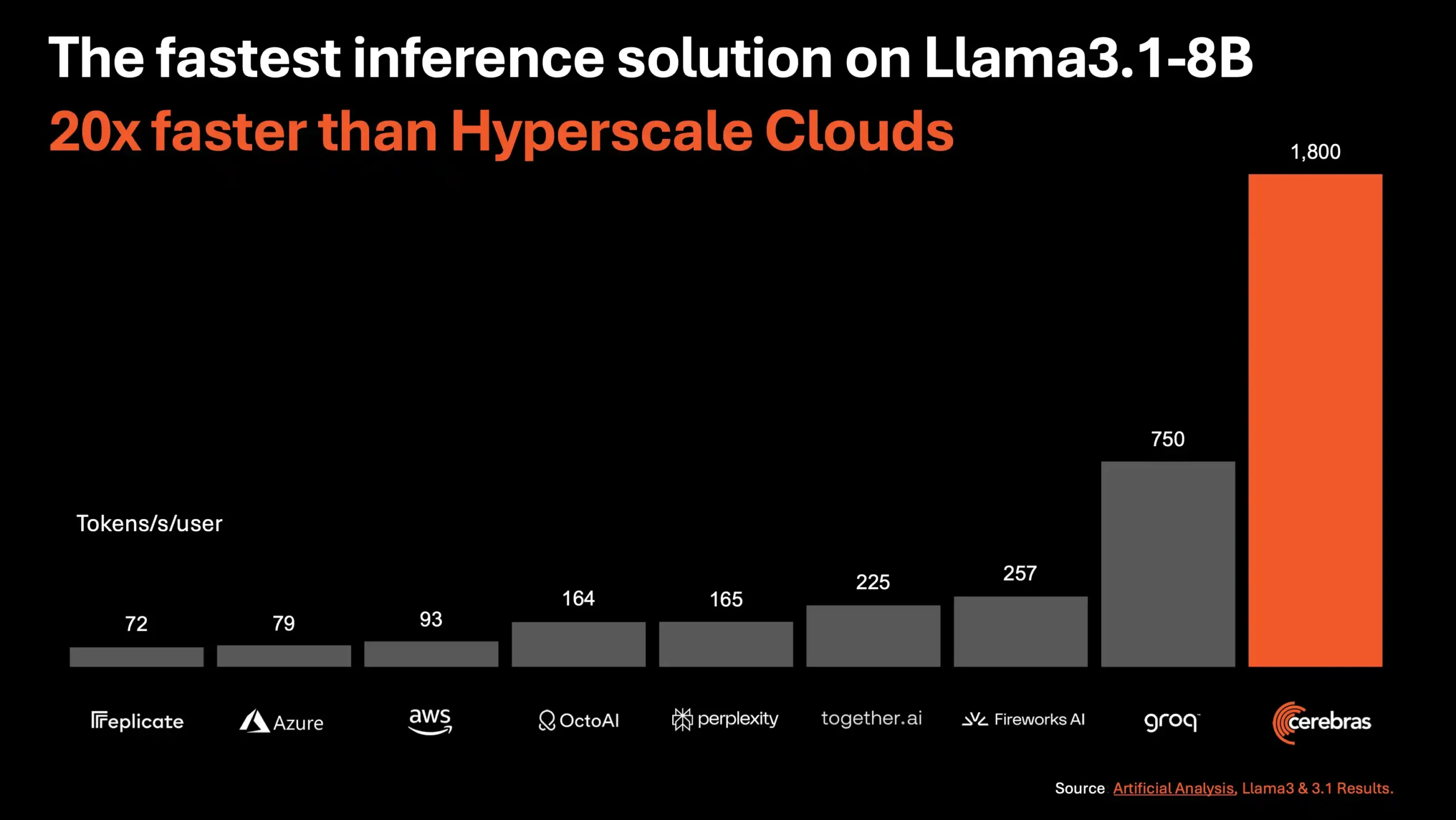
Recent, Cerebras Systems a anunțat lansarea serviciului său de inferență AI, care promite să fie cea mai rapidă soluție de inferență AI din lume. Acest nou serviciu, numit Cerebras Inference, oferă o viteză de procesare de 1.800 de tokeni pe secundă pentru modelul Llama3.1 8B și 450 de tokeni pe secundă pentru Llama3.1 70B, ceea ce reprezintă o viteză de 20 de ori mai mare decât soluțiile bazate pe GPU-urile NVIDIA din norii hiper-scalabili.
Cerebras Inference nu doar că depășește barierele de lățime de bandă ale memoriei, dar oferă și cele mai bune prețuri din industrie, cu 10 cenți pentru un milion de tokeni pentru modelul Llama 3.1 8B și 60 de cenți pentru un milion de tokeni pentru modelul Llama 3.1 70B. Mai mult, serviciul este accesibil dezvoltatorilor începând de astăzi prin acces API, cu limite generoase de rată.
Inovația stă în utilizarea celei de-a treia generații de Wafer Scale Engine, care permite rularea modelului Llama3.1 de 20 de ori mai rapid decât soluțiile GPU la o cincime din preț. Cu o viteză de 1.800 de tokeni pe secundă, Cerebras Inference este de 2,4 ori mai rapid decât Groq în modelul Llama3.1-8B. Pentru modelul Llama3.1-70B, Cerebras este singura platformă care permite răspunsuri instantanee la o viteză uluitoare de 450 de tokeni pe secundă, toate acestea fiind realizate folosind greutăți native de 16 biți pentru model, asigurând cele mai precise răspunsuri.
Această tehnologie revoluționară are potențialul de a transforma modul în care interacționăm cu modelele de limbaj de mare capacitate (LLMs), care sunt esențiale pentru generarea de texte, traduceri, rezumate și multe alte aplicații AI.
Prin depășirea limitărilor de lățime de bandă ale memoriei, Cerebras Inference deschide noi posibilități pentru dezvoltatori și utilizatori, oferind o experiență de inferență AI aproape instantanee.

