


Inteligența artificială a parcurs un drum lung de la recunoașterea simplă a obiectelor la înțelegerea profundă a relațiilor vizuale complexe. Cu lansarea Gemini 2.5, Google redefinește modul în care interacționăm cu imagini prin limbaj natural.
O nouă eră a segmentării imaginii
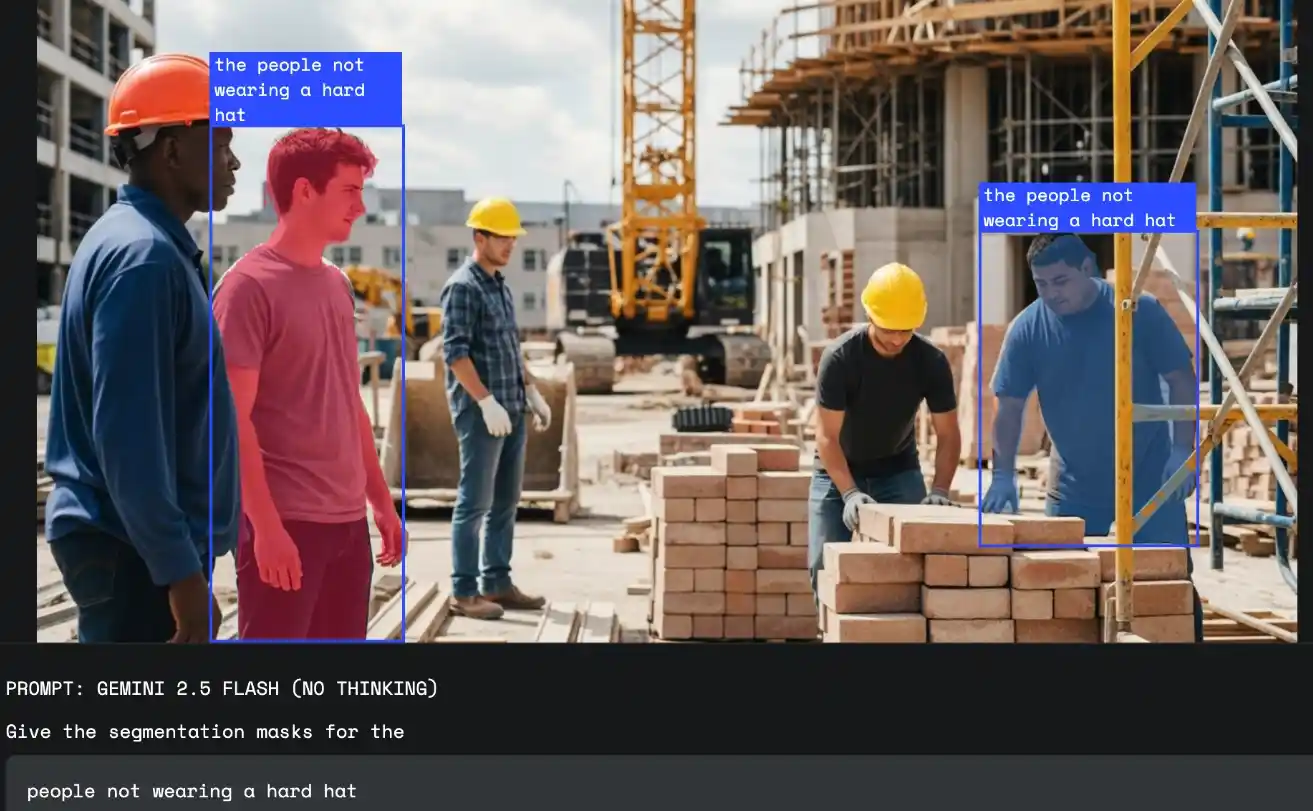
Segmentarea conversațională a imaginilor nu se mai limitează la etichete generice precum „mașină” sau „floare”. Cu Gemini 2.5, putem întreba „care este cea mai îndepărtată mașină?” sau „arată-mi persoanele care nu stau jos”, iar modelul nu doar recunoaște obiectul ci îi înțelege contextul vizual.
Cinci tipuri de interogări care transformă experiența AI
- Relații între obiecte – Identificarea pe bază de poziție, acțiune sau comparații („cartea a treia de la stânga”).
- Logică condiționată – Filtrarea pe criterii logice sau cu negații („mâncare vegetariană”, „cei care nu poartă casca”).
- Concepte abstracte – Segmentarea noțiunilor precum „dezordine” sau „daune” care nu au forme vizuale exacte.
- Detectare text în imagine – Capacitate avansată OCR pentru recunoașterea textului contextual.
- Etichete multilingve – Interogări în diverse limbi fără constrângeri lingvistice.
Aplicații remarcabile
- Design creativ – Selecții intuitive prin comenzi vocale, ideal pentru graficieni.
- Siguranța la locul de muncă – Automatizarea monitorizării prin identificarea angajaților care încalcă normele.
- Asigurări și daune – Evaluarea vizuală precisă a daunelor, separând „reflexia” de „zgârieturi”.
Beneficii pentru dezvoltatori
- Flexibilitate ridicată în interogare prin limbaj natural.
- API unic, rapid de implementat.
- Acces la demo-uri interactive în Google AI Studio sau Colab Python.
Gemini 2.5 nu este doar un model AI – este un pas către o inteligență vizuală care comunică intuitiv, contextual și într-o manieră relevantă pentru diverse industrii.



